Teniendo ya el componente que nos permite generar una cadena de conexión, procedamos a crear un componente que cree un diálogo para utilizar dicha clase, desde Windows Forms.
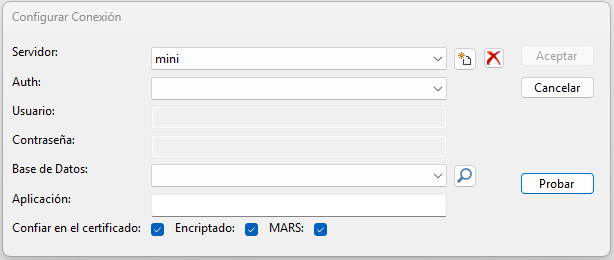
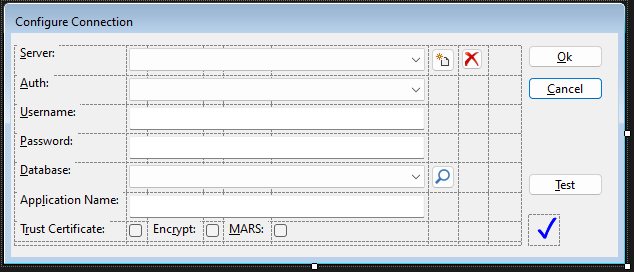
La interfaz de usuario será la siguiente:
Para ello, generaremos un proyecto de tipo biblioteca de clases, al cual agregaremos un formulario de Windows (aunque sea biblioteca de clases), con la interfaz requerida.
Nótese que la primera imagen presenta los literales en español, mientras que, en diseño, los textos están en inglés. Esto es así, porque estamos operando con localización del componente.
El proyecto tiene una clase, con un único método para obtener la cadena de conexión:
Un detalle importante es que el constructor del formulario NO es público, sino internal. De esa forma, no se puede crear una instancia del formulario desde otro proyecto, sino que, necesariamente, debe utilizarse el método PromptForConnection de la clase estática.
El formulario maneja la interactividad, validación, etc. que corresponde a los distintos controles de captura de datos.
Además, reaccionará ante el evento del componente para habilitar o deshabilitar los controles de captura de usuario y contraseña, cuando corresponda.
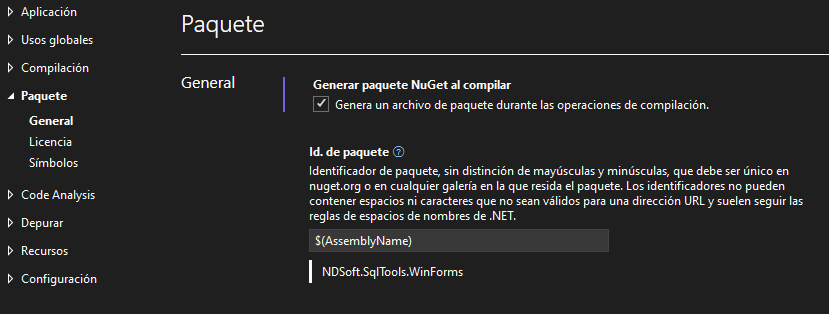
Finalmente, en las propiedades del proyecto, habilitaremos el empaquetado, lo que permitirá que dispongamos de un paquete Nuget con nuestro componente, para agregar a los proyectos en los que lo necesitemos.
El paquete se generará dentro de la carpeta bin, en la carpeta que corresponda al perfil de compilación (Debug, Release).
During this post, I explained how to get information from a database in JSON format. In this one, I will show you how to store information sent to the database in JSON format.
I will use a very common scenario, storing a master-detail combination. For this, I use the Order-Order Details tables in Northwind database, which you can get here.
The goal is to store a new Order, with several Order Details in the same procedure, by using T-SQL OPENJSON.
Like a cooking recipe, I will explain this step by step.
Define the JSON schema.
We want to store the information received in the Order Details table, so its schema will be the schema received in the JSON information.
Simply get the Order Details schema and remove the NOT NULL modifiers. This will be used in the WITH modifier of the OPENJSON statement this way:
It must have parameters to receive all the data for the Orders Table’s columns, and one more containing the entire JSON information for the Order Details table. Notice the OrderID parameter is declared as OUTPUT, so the calling code could retrieve the new Order ID for the inserted row.
For this, the procedure must use the IDENT_CURRENT function.
SET@OrderID=IDENT_CURRENT('[Orders]');
Insert the Order Details using OPENJSON.
In this case, using Insert – select statement, and OPENJSON from the Details parameter as source, declaring it with the previously obtained schema. Notice the utilization of the @OrderID parameter for the Order Id value in each row.
INSERTINTO[Order Details]([OrderID],[ProductID],[UnitPrice],[Quantity],[Discount])SELECT@OrderID/* Using the new Order ID*/,[Productid],[UnitPrice],[Quantity],[Discount]FROMOPENJSON(@Details)WITH([OrderID][INT],[ProductID][INT],[UnitPrice][MONEY],[Quantity][SMALLINT],[Discount][REAL]);
The C# code.
Define the Order and Order Details entities in your Application.
I created a simple C# Console Application Sample. In it, the Order and Order_Details has been defined by using the Paste Special Paste JSON as Classes feature in Visual Studio. You can see the step by step here.
The Insert routine in the main program.
The code creates a new instance of the Order class, with values,
Orderorder=new(){CustomerID="ALFKI",EmployeeID=1,OrderDate=DateTime.UtcNow,RequiredDate=DateTime.UtcNow.AddDays(5),ShipAddress="Obere Str. 57",ShipCity="Berlin",Freight=12.05F,ShipCountry="Germany",ShipName="Alfreds Futterkiste",ShipPostalCode="12209",ShipRegion=null,ShipVia=1};
Then get information from a previously defined set, (as JSON), to have an array of Order Details.
// Create the details. To Avoid a long code, just get it from a JSON samplevardetails=System.Text.Json.JsonSerializer.Deserialize<OrderDetail[]>(InsertUsingJSONSample.Properties.Resources.Details);
Create the Connection and Command objects.
A connection object to the database is assigned to a Command object, with the name of the stored procedure as text, which is defined as a Stored Procedure command type.
By using this method, you reduce the calls between your app and the database server, optimizing the response, and including the entire store process in a unique implicit transaction.
Sometimes, it is not only important to know when and who perform the last change but trace all the changes to the data in certain important tables.
Big applications, require security behaviors and traceability. And better more important, they must be maintained independently of the applications, since more than one application could modify the same database.
And here is where triggers come to rescue.
Of course, I am not saying you must implement business rules in triggers (or even in Stored Procedures).
Business rules are rules, not data manipulation, even when in some SPECIALcases, you must implement some in database objects, but this is not the generic case. (We will discuss this in several other posts in the future).
How it works
To store any change, we need a COPY of the data each time it is about changed. So, we need another table with the same definition than the original. Moreover, it is good to store who and when the change was performed.
The stored procedure creates a new table, based in the source table definition, adding the following columns.
Column
Data Type
Usage
DateChanged
datetime2(7)
When
UserChanged
nvarchar(150)
Who
Action
nvarchar(15)
How
The stored procedure receives an optional parameter for the destination schema. If it is provided, the table denomination will be the destination schema and the same table name than the original. If not, then the history table will be named like the source one, plus the “_Hist” suffix.
Once the table exists, the procedure must create Triggers for Insert, update and delete changes over the source table.
How the triggers work?
A trigger is a T-SQL code which is executed automatically when something happens with one or more rows in a table. The code could be linked to one or more of the three major events: Insertion, update or deletion. Meanwhile the trigger is running, a special table, called inserted, contains the new values in change, and another table, called delete, contains the old values. Notice that this tables could contains more than one row, in case the action that start the process, manipulates one or more rows, like in one massive update. From the trigger point of view, there is no update, but a delete and insert combined. So, inside the trigger, depending on the action, you can have one or both “virtual” tables, as follows.
Action
inserted
deleted
Insert
X
Update
X
X
Delete
X
In this example, the trigger will store in the historical table a new entry with the row (or rows) are inserted. And entries with one or more deleted rows in updates or deletes, to persist the older version of the rows.
CREATETRIGGER [dbo].[EmployeeTerritories_TInsert]
ON [dbo].[EmployeeTerritories]
AFTERINSERTASBEGINSETNOCOUNTON;--Insert a new ow in historical tableINSERTINTO [dbo].[EmployeeTerritories_Hist]
(
[EmployeeID]
, [TerritoryID]
, [DateChanged]
, [UserChanged]
, [Action]
)SELECT
[O].[EmployeeID]
, [O].[TerritoryID]
,SYSUTCDATETIME()-- The exact moment of the insert,USER_NAME()-- The user performing the Insert,'Insert'FROM
[inserted] [O];END;
CREATETRIGGER [dbo].[EmployeeTerritories_TUD]
ON [dbo].[EmployeeTerritories]
AFTERUPDATE,DELETEASBEGINDECLARE
@Action NVARCHAR(15)='Update';/*If there is no rows in inserted table, then it is not an update*/IFNOTEXISTS(SELECT*FROM
[inserted]
)BEGINSET @Action ='Delete';END;SETNOCOUNTON;INSERTINTO [dbo].[EmployeeTerritories_Hist]
(
[EmployeeID]
, [TerritoryID]
, [DateChanged]
, [UserChanged]
, [Action]
)SELECT
[O].[EmployeeID]
, [O].[TerritoryID]
,SYSUTCDATETIME(),USER_NAME(), @Action
FROM
[deleted] [O];END;
So, using the same methodology than in the SP Builder post, with a Table Type variable to collect the columns of the original table, the procedure builds the triggers’ scripts to create them with sp_executesql .
You can found the script fot the SP Create Triggershere.
When things are complex, and it is preferable to not use any ORM like EF, or the database needs to be secured, probably you prefer to use SQL Server Stored procedures.
However, it happens that in those cases, the database uses to have hundreds of tables, and it takes a lot of time to write the standard procedures for CRUD operations for them. This code helps you to build the Insert, Update and Delete procedure for each table. In all cases, the task is performed in just one row, using the Primary key to identify it for update and delete.
How it works.
By getting information from the INFORMATION_SCHEMA view, and using some special system tables like sys.columns and sys.computed_columns, the code retrieves the information for the required table.
The information is stored in a table variable which contains columns to make easier to build the different parts of the sentence, like adding parenthesis, default values, etc. which contains data as you can see in the next image
Then, several queries against the table variable constructs the parameters, sentence, and where segments of the different procedures.
In this case, I will not explain each part. Most of it use STRING_AGG to concatenate the different parts.
However, some comments about the different “issues” I found making this:
The parameters for the Insert procedures, include an OUTPUT statement, in case a column has identity specification to get the value for the inserted row. To do so, the procedure uses IDENT_CURRENT function. But the parameters for Update and Delete do not need the OUTPUT.
The computed columns must not be inserted or updated, so must be excluded of the procedure. This happens in case a column is of timestamp datatype as well.
Just to be sure what the script generates, the results are printed so you can review them.
If you want to use this several times during your development, you can use this second script, which add this as a Stored Procedure, so you can call it just passing the table name, and, when needed, the schema name.
Moreover, it accepts a third parameter, to perform the procedures’ creation directly.
Finally, if you want to use the procedure for all the tables of a database at once, just use this sentence for creating a complete script.
During the develop and testing of any applications, probably you need to clean up test data, in order to test from scratch.
In SQL Server, you have the TRUNCATE TABLE statement to perform this.
However, the statement execution will fail if the table has references to other tables.
This code snippet allows you to truncate a table, avoiding the problem, by removing the relations, truncating the table and reestablishing the relations.
sp_fkeys
In this code, I use the sp_fkeys system stored procedure, which retrieve the definition of any relationship between tables.
The procedure is an old one, I mean, it exists in several SQL server versions.
That’s the reason some of the parameters are about owners. In older versions, the objects belong to users, and that is the reason for name them “owners”.
However, consider that when speaking about owners in objects, in fact we are talking about schemas.
The snippet
These are the steps the snippet performs.
The first step is declaring the schema and the name of the table to be truncated. (We will define how to manage this in a Stored procedure later).
When retrieving the information of the relationships, the return value uses one row for each column implied ion a relation. So, if a relation is using a composite key, there will be more than one row for the same relation.
It is needed to consolidate this, to define just one entry by relation, with the columns defines as a comma separated list, for the re-creation of them later.
a second in memory table is defined to process the consolidation.
There is a chance no relationships exist. The snippet check if this happen, to proceed directly to the truncation of the table.
DECLARE
@References SMALLINT;SELECT
@References =COUNT(*)FROM
@FKSTableVar;IF @References >0--there are relationshipsBEGIN
It is possible that the tables using our candidate table as reference, have rows with referenced values. In that case, it is impossible to truncate the table, or the relationships will be broken. To avoid this, the snippet dynamically creates a script to sum de row-count of all the child tables. In case there are rows, the process aborts with an error.
DECLARE
@Counters NVARCHAR(MAX);SELECT
@Counters =STRING_AGG('(select count(*) from ['+
[FKTABLE_OWNER] +'].['+
[FKTABLE_NAME] +'])','+')FROM
@FKSTableVar;SET @Counters ='Select @ForeignRows='+
@Counters;PRINT @Counters;DECLARE
@ForeignRows INT;EXEC [sp_executesql]@Counters
,N'@ForeignRows int OUTPUT', @ForeignRows OUTPUT;SELECT
@ForeignRows;IF @ForeignRows >0BEGINRAISERROR('There are dependent rows in other tables',10,1);END;ELSE
If it is ok to proceed, two dynamically generated scripts is built, using the STRING_AGG function again, one for drop the relationships of the table, and other for recreate them after the truncate.
Finally, in case there were relationships, the script for recreating is executed, finishing the process.
IF @References >0BEGIN--there are relationshipsEXEC [sp_executesql]@CreateRefs;END;
Using the sp_executesql procedure
A special note about the use of sp_executesql system store procedure. It can just execute a string containing a T-SQL script, but it can use parameters. For that purpose, the parameters must be declared in a second string parameter and passed one by one as the next parameters. Notice the string containing the script, as well as the parameters declaration MUST BE nvarchars.
The snippet as store procedure.
Of course, you can define this snippet as a stored procedure in your database during the devlopment process, to facilitate the execution.
I propose you to have it in a separate schema, as well as any other «tool» for your development work.
This can be defined by using the two first variables declared in the snippet as parameters of the procedure.
CREATEPROCEDURE [Development].[TruncateX]
@TableName SYSNAME, @TableSchema SYSNAME=NULLASBEGINSETNOCOUNTON;SET @TableSchema =ISNULL(@TableSchema,'dbo');-- assume the dbo schema by default
You can found the snippet and the Stored Procedure at my GitHub repository, SqlSamples.
Finally, I’ll add projects to use stored procedures instead of statements constructed in code.
Moreover, and based on the recommendation of a greater entity framework expert than me, I added «AsNoTracking()» to the Entity Framework LINQ query set to Generating a REST API (JSON)[2].
The Stored Procedure.
This is the stored procedure which receives the country ID, the date from and date to, and the page to display.
Is the stored procedure which is responsible for setting values that are appropriate to the date parameters, rather than setting them from the component in C#.
Exactly the same, but with «FOR JSON PATH» at the end, is used in the project that uses pure code.
El Cambio en Entity Framework
Based on the proposal and comment, the code is as follows:
public IEnumerable<OwidCovidDatum> GetCountryData(
intCountryId,
DateTime?fromDate=null,
DateTime?toDate=null,
intPage=1)
{
fromDate=fromDate??
(from el in _context.OwidCovidData orderby el.Date select el.Date).FirstOrDefault();
toDate=toDate??
(from el in _context.OwidCovidData orderby el.Date descendingselect el.Date).FirstOrDefault();
return (from OwidCovidDatum el in
_context.OwidCovidData
.Where(x=> x.Date>=fromDate && x.Date<=toDate && x.CountriesId==CountryId)
.Skip((Page-1)*100)
.Take(100) select el).AsNoTracking().ToList();
}
Dapper Using Stored Procedure
We use Dapper’s stored procedure execution capability, which is capable of assign values to parameters by name matching.
publicasyncTask<string>GetCountryData(intCountryId,DateTime?fromDate=null,DateTime?toDate=null,intPage=1){varresult=await_dal.GetDataAsync("[Owid Covid Data Get By Country]",new{fromDate,toDate,CountryId,Page});stringjson=JsonSerializer.Serialize(result,newJsonSerializerOptions(){WriteIndented=true,ReferenceHandler=ReferenceHandler.Preserve});returnjson;}
Code using Stored Procedure
In the case of direct code, we assign the parameters one by one, also specifying the data type, which allows greater specificity.
publicasyncTask<string>GetCountryData(intCountryId,DateTime?fromDate=null,DateTime?toDate=null,intPage=1){varcommand=_dal.CreateCommand("[Owid Covid Data Get By Country JSON]");command.Parameters.Add("@fromDate",System.Data.SqlDbType.SmallDateTime).Value=fromDate;command.Parameters.Add("@toDate",System.Data.SqlDbType.SmallDateTime).Value=toDate;command.Parameters.Add("@CountryId",System.Data.SqlDbType.Int).Value=CountryId;command.Parameters.Add("@skip",System.Data.SqlDbType.Int).Value=Page;varjson=await_dal.GetJSONDataAsync(command);returnjson;}
Performance
The graph shows that even when you use features that improve effectiveness, the simplicity of the code improves performance.
That is, for better response to the user, more time should be invested by developers in improving their development.
As a detail, stored procedure calls directly make calls to the SP, instead of using, as we saw in the previous post, sp_executesql.
EXEC[Owid Covid Data Get By Country]@fromDate=NULL,@toDate=NULL,@CountryId=4,@Page=3;
Aquí, finalmente, agregaré proyectos para utilizar procedimientos almacenados en lugar de sentencias construidas en el código.
De paso, y por recomendación de un mayor experto que yo en Entity Framework, agregué «AsNoTracking()» a la consulta LINQ de Entity Framework establecida en Generando una API REST (JSON) [2].
El procedimiento Almacenado.
Este es el procedimiento almacenado que recibe, el Id de país, la fecha desde y la fecha hasta, y la página a mostrar.
Es el procedimiento almacenado el responsable de establecer valores adecuados a los parámetros de fecha, en lugar de establecerlos desde el componente en C#.
Exactamente igual, pero con «FOR JSON PATH» al final, se usa en el proyecto que utiliza código puro.
El Cambio en Entity Framework
Basado en la propuesta y comentario, el código queda como sigue:
public IEnumerable<OwidCovidDatum> GetCountryData(
intCountryId,
DateTime?fromDate=null,
DateTime?toDate=null,
intPage=1)
{
fromDate=fromDate??
(from el in _context.OwidCovidData orderby el.Date select el.Date).FirstOrDefault();
toDate=toDate??
(from el in _context.OwidCovidData orderby el.Date descendingselect el.Date).FirstOrDefault();
return (from OwidCovidDatum el in
_context.OwidCovidData
.Where(x=> x.Date>=fromDate && x.Date<=toDate && x.CountriesId==CountryId)
.Skip((Page-1)*100)
.Take(100) select el).AsNoTracking().ToList();
}
Dapper Usando Procedimientos Almacenados
Utilizamos la capacidad de ejecución de procedimientos almacenados de Dapper, que es capaz de asignar valores a los parámetros por coincidencia de nombres.
publicasyncTask<string>GetCountryData(intCountryId,DateTime?fromDate=null,DateTime?toDate=null,intPage=1){varresult=await_dal.GetDataAsync("[Owid Covid Data Get By Country]",new{fromDate,toDate,CountryId,Page});stringjson=JsonSerializer.Serialize(result,newJsonSerializerOptions(){WriteIndented=true,ReferenceHandler=ReferenceHandler.Preserve});returnjson;}
Código usando Procedimientos Almacenados
En el caso del código directo, asignamos los parámetros uno a uno, especificando además el tipo de dato, que permite una mayor especificidad.
publicasyncTask<string>GetCountryData(intCountryId,DateTime?fromDate=null,DateTime?toDate=null,intPage=1){varcommand=_dal.CreateCommand("[Owid Covid Data Get By Country JSON]");command.Parameters.Add("@fromDate",System.Data.SqlDbType.SmallDateTime).Value=fromDate;command.Parameters.Add("@toDate",System.Data.SqlDbType.SmallDateTime).Value=toDate;command.Parameters.Add("@CountryId",System.Data.SqlDbType.Int).Value=CountryId;command.Parameters.Add("@skip",System.Data.SqlDbType.Int).Value=Page;varjson=await_dal.GetJSONDataAsync(command);returnjson;}
Rendimiento
El gráfico muestra que, aún cuando se utilizan características que mejoran la efectividad, la simpleza del código mejora el rendimiento.
O sea, para mejor respuesta al usuario, se deberá invertir más tiempo de los desarrolladores en mejorar su desarrollo.
Como detalle, las llamadas de procedimiento almacenado, realizan directamente llamadas al mismo, en lugar de utilizar, como vimos en la publicación anterior, sp_executesql.
EXEC[Owid Covid Data Get By Country]@fromDate=NULL,@toDate=NULL,@CountryId=4,@Page=3;
I’m not going to go into detail here describing what is REST (Representational State Transfer) an API (Application Programming Interface) or JSON (JavaScript Object Notation). I start from the base that is already known to which we refer.
In this case, using the database published in the previous entry Data for demos, I will present how to expose the information from that database, in a read-only API.
At the same time, I will try to show advantages and disadvantages of different methods to achieve the same objective.
Entity Framework
Although in general, I dislike its use, I will try to include it in each demonstration, to see what advantages it brings, and the disadvantages that arise.
The project within the solution is ApiRestEF
Dapper
As a data access package/library, it allows you to easily obtain information from databases.
The project, within the solution is ApiRestDapper
Coding directly
In this case, I’ll be showing how to do, the same thing, but step by step, without libraries.
The project, within the solution is ApiRestCode
First requirement
A method is needed to obtain the information that is displayed, for a continent indicated as a parameter.
Continent
Country
Total Cases
Total Deaths
Total Cases per Million
Total Deaths per Million
Population
Population Density
GDP per Capita
Africa
Seychelles
12466
46
126764
468
98340
208
26382
Africa
Cape Verde
31433
271
56535
487
555988
136
6223
Africa
Tunisia
362658
13305
30685
1126
11818618
74
10849
Africa
South Africa
1722086
57410
29036
968
59308690
47
12295
Africa
Libya
188386
3155
27416
459
6871287
4
17882
Africa
Botswana
59480
896
25293
381
2351625
4
15807
Africa
Namibia
61374
968
24154
381
2540916
3
9542
Africa
Eswatini
18705
676
16123
583
1160164
79
7739
Africa
Morocco
522765
9192
14163
249
36910558
80
7485
Africa
Djibouti
11570
154
11711
156
988002
41
2705
Africa
Gabon
24696
156
11096
70
2225728
8
16562
Entity Framework
The code used obtains the continent and its constituent countries in a single query but required to go through the countries, to obtain from each one, the demographic data.
As I said, I don’t like EF and maybe that’s why my research into methods to do it, may not have found another way.
Of course, if someone offers another proposal in the comments, I’ll add it here, and I’ll also proceed to evaluate the corresponding metric.
For the case of implementation with Dapper, we directly use the «DapperRow» types as the query return, thus decreasing the mapping between columns and properties. If defined classes were used, the response time would surely be longer.
Finally, for direct query by code, we optimize using the FOR JOSN modifier, and then directly obtaining the resulting JSON string.
publicasyncTask<ActionResult<string>>GetContinent(intid){stringsql=@" SELECT
[C].[Continent]
, [CO].[Country]
, [D].[total_cases]
, [D].[total_deaths]
, [D].[total_cases_per_million]
, [D].[total_deaths_per_million]
, [D].[population]
, [D].[population_density]
, [D].[gdp_per_capita]
FROM
[OwidCountriesData] AS [D]
INNER JOIN
[Continents] AS [C]
ON [D].[ContinentId] = [C].[Id]
INNER JOIN
[Countries] AS [CO]
ON [D].[CountriesId] = [CO].[Id]
WHERE([C].[Id] = @continent)
ORDER BY
[D].[total_cases_per_million] DESC FOR JSON AUTO, INCLUDE_NULL_VALUES, ROOT('CountriesInfo');";SqlCommandcom=_dal.CreateCommand(sql);com.Parameters.AddWithValue("@continent",id);returnawait_dal.GetJSONDataAsync(com);}
Note
In both the Dapper and code projects, a minimal data access layer was built to emulate functionality similar to that provided by EF-generated code.
Performance
The graph below shows the comparison in CPU utilization, lifetime, and disk reads, in each of the cases. A picture is worth a thousand words. 🙂
In the graph, values are evaluated only from the point of view of the database, not the .Net code, nor its runtime. I will add this in the next installment.
No voy a entrar aquí en detalles de descripción de lo que es REST (Representational State Transfer) una API (Application Programming Interface) o JSON (JavaScript Object Notation). Parto de la base que ya se conoce a que nos referimos.
En este caso, utilizando la base de datos publicada en la entrada anterior Datos para demos, presentaré como exponer la información de esa base, en una API de sólo lectura.
Al mismo tiempo, intentaré mostrar ventajas y desventajas de distintos métodos para lograr el mismo objetivo.
Entity Framework
Aunque en líneas generales, me disgusta bastante su utilización, intentaré incluirlo en cada demostración, por ver que ventajas aporta, y los inconvenientes que surjan.
El proyecto dentro de la solución es ApiRestEF
Dapper
Como paquete/biblioteca de acceso a datos, permite fácilmente obtener información de bases de datos.
El proyecto, dentro de la solución es ApiRestDapper
Código directo
En este caso, estaré mostrando como hacer, lo mismo, pero paso a paso, sin bibliotecas.
El proyecto, dentro de la solución es ApiRestCode
Primer requisito.
Se necesita un mecanismo por el cual obtener la información que se muestra, para un continente indicado como parámetro.
Continent
Country
Total Cases
Total Deaths
Total Cases per Million
Total Deaths per Million
Population
Population Density
GDP per Capita
Africa
Seychelles
12466
46
126764
468
98340
208
26382
Africa
Cape Verde
31433
271
56535
487
555988
136
6223
Africa
Tunisia
362658
13305
30685
1126
11818618
74
10849
Africa
South Africa
1722086
57410
29036
968
59308690
47
12295
Africa
Libya
188386
3155
27416
459
6871287
4
17882
Africa
Botswana
59480
896
25293
381
2351625
4
15807
Africa
Namibia
61374
968
24154
381
2540916
3
9542
Africa
Eswatini
18705
676
16123
583
1160164
79
7739
Africa
Morocco
522765
9192
14163
249
36910558
80
7485
Africa
Djibouti
11570
154
11711
156
988002
41
2705
Africa
Gabon
24696
156
11096
70
2225728
8
16562
Entity Framework
El código utilizado obtiene el continente y sus países constitutivos en una sola consulta pero requirió recorrer los países, para obtener de cada uno, los datos demográficos.
Como ya dije, no me gusta EF y quizás por ello, mi investigación de métodos para hacerlo, puede no haber encontrado otra forma.
Por supuesto, si alguien ofrece otra propuesta en los comentarios, la agregaré aquí, y también procederé a evaluar la métrica correspondiente.
para el caso de la implementación con Dapper, utilizamos directamente los tipos «DapperRow» como retorno de la consulta, disminuyendo así el mapeo entre columnas y propiedades. De usarse clases definidas, seguramente el tiempo de respuesta sería mayor.
Finalmente, para la consulta directa por código, optimizamos utilizando el modificador FOR JOSN, y obteniendo entonces directamente la cadena JSON resultante.
publicasyncTask<ActionResult<string>>GetContinent(intid){stringsql=@" SELECT
[C].[Continent]
, [CO].[Country]
, [D].[total_cases]
, [D].[total_deaths]
, [D].[total_cases_per_million]
, [D].[total_deaths_per_million]
, [D].[population]
, [D].[population_density]
, [D].[gdp_per_capita]
FROM
[OwidCountriesData] AS [D]
INNER JOIN
[Continents] AS [C]
ON [D].[ContinentId] = [C].[Id]
INNER JOIN
[Countries] AS [CO]
ON [D].[CountriesId] = [CO].[Id]
WHERE([C].[Id] = @continent)
ORDER BY
[D].[total_cases_per_million] DESC FOR JSON AUTO, INCLUDE_NULL_VALUES, ROOT('CountriesInfo');";SqlCommandcom=_dal.CreateCommand(sql);com.Parameters.AddWithValue("@continent",id);returnawait_dal.GetJSONDataAsync(com);}
Aclaración
Tanto en el proyecto Dapper como en el de código, se construyó una capa de acceso a datos mínima, para emular similar funcionalidad a la brindada por el código generado por EF.
Rendimiento
El gráfico inferior muestra la comparativa en utilización de CPU, tiempo de duración, y lecturas a disco, en cada uno de los casos. Una imagen, vale más que mil palabras. 🙂
En el gráfico, solo se evalúan valores desde el punto de vista de la base de datos, no del código .Net, ni su tiempo de ejecución. Agregaré esto en la próxima entrega.
Segunda época del rockblog "Atascado en los 70". VIEJAS canciones y artistas PASADOS DE MODA. Tratamos al lector de usted y escribimos "rocanrol" y "roquero" con ortografía castellana.




![GENERATING A REST API (JSON) [3]](https://universidadnetdotes.files.wordpress.com/2021/06/image-3.png?w=672&h=372&crop=1)



