Teniendo ya el componente que nos permite generar una cadena de conexión, procedamos a crear un componente que cree un diálogo para utilizar dicha clase, desde Windows Forms.
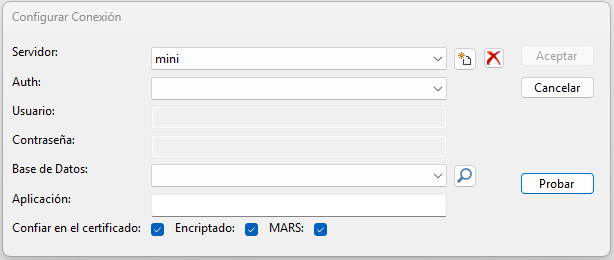
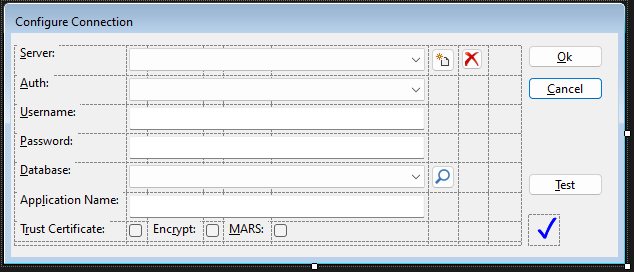
La interfaz de usuario será la siguiente:
Para ello, generaremos un proyecto de tipo biblioteca de clases, al cual agregaremos un formulario de Windows (aunque sea biblioteca de clases), con la interfaz requerida.
Nótese que la primera imagen presenta los literales en español, mientras que, en diseño, los textos están en inglés. Esto es así, porque estamos operando con localización del componente.
El proyecto tiene una clase, con un único método para obtener la cadena de conexión:
Un detalle importante es que el constructor del formulario NO es público, sino internal. De esa forma, no se puede crear una instancia del formulario desde otro proyecto, sino que, necesariamente, debe utilizarse el método PromptForConnection de la clase estática.
El formulario maneja la interactividad, validación, etc. que corresponde a los distintos controles de captura de datos.
Además, reaccionará ante el evento del componente para habilitar o deshabilitar los controles de captura de usuario y contraseña, cuando corresponda.
Finalmente, en las propiedades del proyecto, habilitaremos el empaquetado, lo que permitirá que dispongamos de un paquete Nuget con nuestro componente, para agregar a los proyectos en los que lo necesitemos.
El paquete se generará dentro de la carpeta bin, en la carpeta que corresponda al perfil de compilación (Debug, Release).
During this post, I explained how to get information from a database in JSON format. In this one, I will show you how to store information sent to the database in JSON format.
I will use a very common scenario, storing a master-detail combination. For this, I use the Order-Order Details tables in Northwind database, which you can get here.
The goal is to store a new Order, with several Order Details in the same procedure, by using T-SQL OPENJSON.
Like a cooking recipe, I will explain this step by step.
Define the JSON schema.
We want to store the information received in the Order Details table, so its schema will be the schema received in the JSON information.
Simply get the Order Details schema and remove the NOT NULL modifiers. This will be used in the WITH modifier of the OPENJSON statement this way:
It must have parameters to receive all the data for the Orders Table’s columns, and one more containing the entire JSON information for the Order Details table. Notice the OrderID parameter is declared as OUTPUT, so the calling code could retrieve the new Order ID for the inserted row.
For this, the procedure must use the IDENT_CURRENT function.
SET@OrderID=IDENT_CURRENT('[Orders]');
Insert the Order Details using OPENJSON.
In this case, using Insert – select statement, and OPENJSON from the Details parameter as source, declaring it with the previously obtained schema. Notice the utilization of the @OrderID parameter for the Order Id value in each row.
INSERTINTO[Order Details]([OrderID],[ProductID],[UnitPrice],[Quantity],[Discount])SELECT@OrderID/* Using the new Order ID*/,[Productid],[UnitPrice],[Quantity],[Discount]FROMOPENJSON(@Details)WITH([OrderID][INT],[ProductID][INT],[UnitPrice][MONEY],[Quantity][SMALLINT],[Discount][REAL]);
The C# code.
Define the Order and Order Details entities in your Application.
I created a simple C# Console Application Sample. In it, the Order and Order_Details has been defined by using the Paste Special Paste JSON as Classes feature in Visual Studio. You can see the step by step here.
The Insert routine in the main program.
The code creates a new instance of the Order class, with values,
Orderorder=new(){CustomerID="ALFKI",EmployeeID=1,OrderDate=DateTime.UtcNow,RequiredDate=DateTime.UtcNow.AddDays(5),ShipAddress="Obere Str. 57",ShipCity="Berlin",Freight=12.05F,ShipCountry="Germany",ShipName="Alfreds Futterkiste",ShipPostalCode="12209",ShipRegion=null,ShipVia=1};
Then get information from a previously defined set, (as JSON), to have an array of Order Details.
// Create the details. To Avoid a long code, just get it from a JSON samplevardetails=System.Text.Json.JsonSerializer.Deserialize<OrderDetail[]>(InsertUsingJSONSample.Properties.Resources.Details);
Create the Connection and Command objects.
A connection object to the database is assigned to a Command object, with the name of the stored procedure as text, which is defined as a Stored Procedure command type.
By using this method, you reduce the calls between your app and the database server, optimizing the response, and including the entire store process in a unique implicit transaction.
In our current globalized world, at this time, any web site must be multilingual, enabling the user to select the language to use.
Moreover, a global company needs to know from which country the user connected.
A lot of sites, more of the streaming services as examples, identifies the country based on the IP address. Which could be a mistake, since a lot of people are in a different country of which belongs to.
Anyway, your database must need a language list and a countries list.
This post shows you a sample application which, using the standardized languages and countries from .Net Framework, and adding some information from external sources, set up some tables to manage this in your databases.
System.Globalization Namespace
The tool uses information from the System.Globalization namespace, which appears with .Net Framework from it very beginning.
Indicates if it is just a language or a language and country specification
Finally, I get information from two external sources. I got the GPS coordinates of each country from here meanwhile the flag’s pictures are from here. You can found the urls inside the code as well.
Storage’s schema.
Languages/Countries database schema
The tool create 3 tables as you can see in the Diagram.
It is necessary this way, because some countries use more than one language, and the relationship must be preserved.
The tables have a InUse column, to enable/disable each row for your application. So, you can query the Languages table for all the rows with the InUse value in 1, to display only those languages you desire use, or have enabled.
Note: It is important using nvarchar/nchar data types, since several Native names are in UTF-8 chars.
Using the tool.
The tool expects at least the connection string to your database. It accepts a second parameter for the schema name under the tables will be created. If this value is not provided, the tool assumes “Masters” as schema name.
In any case, the DDL scripts manage the creation of the schema if it does not exist.
The source code of the DataGen solution is in my GitHub.
If you prefer just use a T-SQL script to add the tables, here is the script.
In future posts, I will show some faqncy methods for site AND CONTENT localization.
Sometimes, it is not only important to know when and who perform the last change but trace all the changes to the data in certain important tables.
Big applications, require security behaviors and traceability. And better more important, they must be maintained independently of the applications, since more than one application could modify the same database.
And here is where triggers come to rescue.
Of course, I am not saying you must implement business rules in triggers (or even in Stored Procedures).
Business rules are rules, not data manipulation, even when in some SPECIALcases, you must implement some in database objects, but this is not the generic case. (We will discuss this in several other posts in the future).
How it works
To store any change, we need a COPY of the data each time it is about changed. So, we need another table with the same definition than the original. Moreover, it is good to store who and when the change was performed.
The stored procedure creates a new table, based in the source table definition, adding the following columns.
Column
Data Type
Usage
DateChanged
datetime2(7)
When
UserChanged
nvarchar(150)
Who
Action
nvarchar(15)
How
The stored procedure receives an optional parameter for the destination schema. If it is provided, the table denomination will be the destination schema and the same table name than the original. If not, then the history table will be named like the source one, plus the “_Hist” suffix.
Once the table exists, the procedure must create Triggers for Insert, update and delete changes over the source table.
How the triggers work?
A trigger is a T-SQL code which is executed automatically when something happens with one or more rows in a table. The code could be linked to one or more of the three major events: Insertion, update or deletion. Meanwhile the trigger is running, a special table, called inserted, contains the new values in change, and another table, called delete, contains the old values. Notice that this tables could contains more than one row, in case the action that start the process, manipulates one or more rows, like in one massive update. From the trigger point of view, there is no update, but a delete and insert combined. So, inside the trigger, depending on the action, you can have one or both “virtual” tables, as follows.
Action
inserted
deleted
Insert
X
Update
X
X
Delete
X
In this example, the trigger will store in the historical table a new entry with the row (or rows) are inserted. And entries with one or more deleted rows in updates or deletes, to persist the older version of the rows.
CREATETRIGGER [dbo].[EmployeeTerritories_TInsert]
ON [dbo].[EmployeeTerritories]
AFTERINSERTASBEGINSETNOCOUNTON;--Insert a new ow in historical tableINSERTINTO [dbo].[EmployeeTerritories_Hist]
(
[EmployeeID]
, [TerritoryID]
, [DateChanged]
, [UserChanged]
, [Action]
)SELECT
[O].[EmployeeID]
, [O].[TerritoryID]
,SYSUTCDATETIME()-- The exact moment of the insert,USER_NAME()-- The user performing the Insert,'Insert'FROM
[inserted] [O];END;
CREATETRIGGER [dbo].[EmployeeTerritories_TUD]
ON [dbo].[EmployeeTerritories]
AFTERUPDATE,DELETEASBEGINDECLARE
@Action NVARCHAR(15)='Update';/*If there is no rows in inserted table, then it is not an update*/IFNOTEXISTS(SELECT*FROM
[inserted]
)BEGINSET @Action ='Delete';END;SETNOCOUNTON;INSERTINTO [dbo].[EmployeeTerritories_Hist]
(
[EmployeeID]
, [TerritoryID]
, [DateChanged]
, [UserChanged]
, [Action]
)SELECT
[O].[EmployeeID]
, [O].[TerritoryID]
,SYSUTCDATETIME(),USER_NAME(), @Action
FROM
[deleted] [O];END;
So, using the same methodology than in the SP Builder post, with a Table Type variable to collect the columns of the original table, the procedure builds the triggers’ scripts to create them with sp_executesql .
You can found the script fot the SP Create Triggershere.
Sooner or later, it happens. Someone asks “When this data has been modified? Who changed this information?”
A reliable system must ensure this information could be obtained any time.
In this post I offer you a simple way to add columns to any table you want to preserve the metadata about the last changes.
In another post, I’ll talk about tracking all the changes.
Like in the last posts, I prepare it as stored procedure, which receives two parameters:
The Table Name
The Schema Name (optional) in which case, “dbo” is assumed
The procedure will add the following columns:
Column Name
Information Stored
Default Value
Created by
username in the insert action
CURRENT_USER
Modified By
username in the update action
Creation Date
date & time of the creation
SYSUTCDATETIME
Modification Date
date & time of the update
Note: An «Active» column is added as well, to manage «soft deletes» in case you need it.
Notice there is no default value for update actions, since they are not supported by the database. The values must be provided by application procedures. In fact, they could be provided for the creation process as well, if desired.
Some code highlights
Using a select from INFORMATION_SCHEMA.COLUMNS the procedure detects if the column to add already exists.
DECLARE
@Isthere INT;DECLARE
@CheckForColumn NVARCHAR(300)='select @Isthere =count(*) from INFORMATION_SCHEMA.COLUMNS T where TABLE_SCHEMA=@schema and TABLE_NAME=@TableName and T.COLUMN_NAME=@ColumnName'
Like in other examples I already post, using sp_executesql stored procedure, can execute the T-SQL sentence passing parameters.
The same steps are repeated for the other columns.
In similar way with other previous posts, this stored procedure could be executed over all the tables in a database, using a select from INFORMATION_SCHEMA.TABLES.
When things are complex, and it is preferable to not use any ORM like EF, or the database needs to be secured, probably you prefer to use SQL Server Stored procedures.
However, it happens that in those cases, the database uses to have hundreds of tables, and it takes a lot of time to write the standard procedures for CRUD operations for them. This code helps you to build the Insert, Update and Delete procedure for each table. In all cases, the task is performed in just one row, using the Primary key to identify it for update and delete.
How it works.
By getting information from the INFORMATION_SCHEMA view, and using some special system tables like sys.columns and sys.computed_columns, the code retrieves the information for the required table.
The information is stored in a table variable which contains columns to make easier to build the different parts of the sentence, like adding parenthesis, default values, etc. which contains data as you can see in the next image
Then, several queries against the table variable constructs the parameters, sentence, and where segments of the different procedures.
In this case, I will not explain each part. Most of it use STRING_AGG to concatenate the different parts.
However, some comments about the different “issues” I found making this:
The parameters for the Insert procedures, include an OUTPUT statement, in case a column has identity specification to get the value for the inserted row. To do so, the procedure uses IDENT_CURRENT function. But the parameters for Update and Delete do not need the OUTPUT.
The computed columns must not be inserted or updated, so must be excluded of the procedure. This happens in case a column is of timestamp datatype as well.
Just to be sure what the script generates, the results are printed so you can review them.
If you want to use this several times during your development, you can use this second script, which add this as a Stored Procedure, so you can call it just passing the table name, and, when needed, the schema name.
Moreover, it accepts a third parameter, to perform the procedures’ creation directly.
Finally, if you want to use the procedure for all the tables of a database at once, just use this sentence for creating a complete script.
During the develop and testing of any applications, probably you need to clean up test data, in order to test from scratch.
In SQL Server, you have the TRUNCATE TABLE statement to perform this.
However, the statement execution will fail if the table has references to other tables.
This code snippet allows you to truncate a table, avoiding the problem, by removing the relations, truncating the table and reestablishing the relations.
sp_fkeys
In this code, I use the sp_fkeys system stored procedure, which retrieve the definition of any relationship between tables.
The procedure is an old one, I mean, it exists in several SQL server versions.
That’s the reason some of the parameters are about owners. In older versions, the objects belong to users, and that is the reason for name them “owners”.
However, consider that when speaking about owners in objects, in fact we are talking about schemas.
The snippet
These are the steps the snippet performs.
The first step is declaring the schema and the name of the table to be truncated. (We will define how to manage this in a Stored procedure later).
When retrieving the information of the relationships, the return value uses one row for each column implied ion a relation. So, if a relation is using a composite key, there will be more than one row for the same relation.
It is needed to consolidate this, to define just one entry by relation, with the columns defines as a comma separated list, for the re-creation of them later.
a second in memory table is defined to process the consolidation.
There is a chance no relationships exist. The snippet check if this happen, to proceed directly to the truncation of the table.
DECLARE
@References SMALLINT;SELECT
@References =COUNT(*)FROM
@FKSTableVar;IF @References >0--there are relationshipsBEGIN
It is possible that the tables using our candidate table as reference, have rows with referenced values. In that case, it is impossible to truncate the table, or the relationships will be broken. To avoid this, the snippet dynamically creates a script to sum de row-count of all the child tables. In case there are rows, the process aborts with an error.
DECLARE
@Counters NVARCHAR(MAX);SELECT
@Counters =STRING_AGG('(select count(*) from ['+
[FKTABLE_OWNER] +'].['+
[FKTABLE_NAME] +'])','+')FROM
@FKSTableVar;SET @Counters ='Select @ForeignRows='+
@Counters;PRINT @Counters;DECLARE
@ForeignRows INT;EXEC [sp_executesql]@Counters
,N'@ForeignRows int OUTPUT', @ForeignRows OUTPUT;SELECT
@ForeignRows;IF @ForeignRows >0BEGINRAISERROR('There are dependent rows in other tables',10,1);END;ELSE
If it is ok to proceed, two dynamically generated scripts is built, using the STRING_AGG function again, one for drop the relationships of the table, and other for recreate them after the truncate.
Finally, in case there were relationships, the script for recreating is executed, finishing the process.
IF @References >0BEGIN--there are relationshipsEXEC [sp_executesql]@CreateRefs;END;
Using the sp_executesql procedure
A special note about the use of sp_executesql system store procedure. It can just execute a string containing a T-SQL script, but it can use parameters. For that purpose, the parameters must be declared in a second string parameter and passed one by one as the next parameters. Notice the string containing the script, as well as the parameters declaration MUST BE nvarchars.
The snippet as store procedure.
Of course, you can define this snippet as a stored procedure in your database during the devlopment process, to facilitate the execution.
I propose you to have it in a separate schema, as well as any other «tool» for your development work.
This can be defined by using the two first variables declared in the snippet as parameters of the procedure.
CREATEPROCEDURE [Development].[TruncateX]
@TableName SYSNAME, @TableSchema SYSNAME=NULLASBEGINSETNOCOUNTON;SET @TableSchema =ISNULL(@TableSchema,'dbo');-- assume the dbo schema by default
You can found the snippet and the Stored Procedure at my GitHub repository, SqlSamples.
Then, when a new order is inserted, you can get the next value from the sequence, using this code:
BEGINDECLARE
@GetSeq NVARCHAR(MAX)=replace('SELECT NEXT VALUE FOR OnLineSales.WebCustomers_@@ as OrderNo','@@', @IdCustomer);DECLARE
@OrderNo INT;EXEC [sp_executeSQL]@GetSeq
,N'@OrderNo INT OUTPUT', @OrderNo OUTPUT;INSERTINTO [OnLineSales].[Orders]
(
[IdCustomer]
, [OrderNo]
, [Date]
, [Total]
)VALUES(
@IdCustomer
, @OrderNo
, @Date
, @Total
);END;
This is a simple way to keep separated numbering by other column value.
This is a simple way to keep separated numbering by other column value.
Note As you can see, both statements samples use variables. In fact, they are parameters, since are implemented as stored procedures. This is important, since a normal user, not and admin, dbo, or server admin, must not have DDL permissions, and the CREATE SEQUENCE statement is a DDL one. However, been the Stored Procedure created by an admin, when it is used by another user with EXECUTE permissions, the DDL statement works without raise any error. It is like the normal user “is impersonated” by the stored procedure’s creator, and the SP runs under the security permissions environment of the SP creator.
In this example, we will see how we can test the different versions from a web application.
It is a simple page that calls consecutively the different versions, repeatedly (100), and returns the number of milliseconds involved in the whole process.
To increase the impedance of the evaluation, the option is given in a check box, to perform the same query, 100 times, but for all countries.
In any case, the responses will be in approximately the same proportion.
Performance
As you can see, from the point of view of the client application, the final result is faster with EF than with simple code, exactly the opposite of the performance in the first test.
It should be noted, however, that in that first test, the process requested was not the same at all, since data from different tables were required, while, in this case, the data came from only one.
In any case, the comparison could be established with the second publication of this series, which obtains the same data as the latter.
In any case, this last test has some advantage on the part of EF, compared to the rest.
In other words, let us point out conclusions:
The result is not always as expected. You must try. ALWAYS.
There is no single way to do things. We must investigate to improve the quality of the applications we generate.
An unit test of the final set of the application can lead to false conclusions, since other factors, such as communication, data transformation, etc., also influence performance. That is, unit tests are highly valid for testing functionality, but they are not always valid for evaluating performance.
In fact, most likely, in a real-world application environment, performance results can also change.
Therefore, it is important to monitor the application deployed in production, include counters, logs etc. to have permanent information and be able to periodically evaluate it, to anticipate possible problems.
En este ejemplo, veremos como podemos probar las distintas versiones desde un aplicativo web.
Se trata de una página sencilla que, llama consecutivamente a las distintas versiones, repetidas veces (100), y nos retorna la cantidad de milisegundos implicados en todo el proceso.
Para incrementar la impedancia de la evaluación, se da la opción en una casilla, de realizar la misma consulta, 100 veces, pero para todos los países.
En cualquier caso, las respuestas serán aproximadamente en la misma proporción.
Rendimiento
Como se puede ver, desde el punto de vista de la aplicación cliente, el resultado final es más rápido con EF que con código plano, exactamente lo contrario a la respuesta en la primera prueba.
Es de notar, sin embargo, que en aquella primera prueba, el proceso solicitado no era el mismo en lo absoluto, dado que se requerían datos de distintas tablas, mientras que, en este caso, los datos provienen de una sola.
En todo caso, la comparativa la podríamos establecer con la segunda publicación de esta serie, que obtiene los mismos datos que ésta última.
En cualquier caso, esta última prueba presenta alguna ventaja de parte de EF, respecto del resto.
O sea, puntualicemos conclusiones:
No siempre el resultado es el esperado. Hay que probar. SIEMPRE.
No hay una sola forma de hacer las cosas. Hay que investigar para mejorar la calidad de las aplicaciones que generamos.
Una prueba aislada del conjunto final de la aplicación, puede llevarnos a falsas conclusiones, ya que otros factores, como comunicación, transformación de datos, etc., también influyen en el rendimiento. O sea, las pruebas unitarias son muy validad para comprobar funcionalidad, pero no siempre son válidas para evaluar rendimiento.
De hecho, muy probablemente, en un entorno de una aplicación real, también los resultados de rendimiento pueden cambiar.
Por ello, es importante hacer seguimiento de la aplicación desplegada en producción, incluir contadores, bitácoras etc. para tener información permanente y poder evaluar periódicamente la misma, para adelantarnos a posibles problemas.
Segunda época del rockblog "Atascado en los 70". VIEJAS canciones y artistas PASADOS DE MODA. Tratamos al lector de usted y escribimos "rocanrol" y "roquero" con ortografía castellana.